

昇思人工智能框架峰會(huì) | 昇思MindSpore MoE模型性能優(yōu)化方案,提升訓(xùn)練性能15%+
據(jù)悉,昇思MindSpore開源社區(qū)將于 2025 年 12 月 25日在杭州舉辦昇思人工智能框架峰會(huì)。本次峰會(huì)的昇思人工智能框架技術(shù)發(fā)展與行業(yè)實(shí)踐論壇將討論到昇思MindSpore大模型訓(xùn)練技術(shù)進(jìn)展與實(shí)踐,MindSpore Parallel Training System SIG的核心貢獻(xiàn)者將在昇思開發(fā)者動(dòng)手實(shí)踐workshop設(shè)立開發(fā)者動(dòng)手實(shí)踐體驗(yàn),帶領(lǐng)開發(fā)者體驗(yàn)使用昇思MindSpore大模型訓(xùn)練技術(shù)。本文對(duì)MindSpore 大模型訓(xùn)練技術(shù)進(jìn)行了深入解讀,就業(yè)界關(guān)熱度較高的MoE性能優(yōu)化技術(shù),介紹MindSpore方案。
混合專家模型(Mixture of Experts, MoE)因其在計(jì)算效率與模型容量之間巧妙的平衡作用,能有效緩解解決大模型參數(shù)指數(shù)增長(zhǎng)帶來的計(jì)算壓力的關(guān)鍵技術(shù)之一,正成為構(gòu)建超大規(guī)模神經(jīng)網(wǎng)絡(luò)的核心架構(gòu)。然而,MoE模型引入的復(fù)雜路由機(jī)制,導(dǎo)致通信開銷顯著增長(zhǎng),特別是token dispatch和combine階段,AlltoAll類密集的跨機(jī)大數(shù)據(jù)量通信,成為系統(tǒng)性能的主要瓶頸。針對(duì)這一瓶頸,昇思MindSpore面向大模型訓(xùn)練實(shí)踐,提出了一套MoE性能優(yōu)化方案。
昇思MindSpore MoE性能優(yōu)化方案主要包含機(jī)間通信合并、零冗余通信、AlltoAllV收發(fā)異構(gòu)復(fù)用3項(xiàng)關(guān)鍵技術(shù)。這些技術(shù)協(xié)同作用,系統(tǒng)性地解決了MoE架構(gòu)在大規(guī)模分布式訓(xùn)練中面臨的通信開銷大、斷流頻率高、顯存占用高等核心瓶頸。
機(jī)間通信合并特性
當(dāng)前的流行MoE架構(gòu)存在著專家數(shù)多、單個(gè)專家計(jì)算量小的特點(diǎn)。如DeepSeek V3每個(gè)層的路由專家個(gè)數(shù)高達(dá)256個(gè),在訓(xùn)練實(shí)踐中為了減小顯存壓力往往開啟專家并行(EP),將專家切分到不同的卡上。然而,當(dāng)EP數(shù)大于單個(gè)節(jié)點(diǎn)的的NPU/GPU數(shù)量時(shí),專家會(huì)被切分到不同節(jié)點(diǎn)上,在token dispatch和combine階段,需要進(jìn)行AlltoAll的機(jī)間通信。因機(jī)間帶寬遠(yuǎn)小于機(jī)內(nèi)帶寬,此時(shí),機(jī)間通信不可避免地成為通信性能的瓶頸。
昇思MindSpore團(tuán)隊(duì)針對(duì)這一問題,采用跨機(jī)AllGather通信與機(jī)內(nèi)AlltoAll通信相結(jié)合的方式,解決AlltoAll機(jī)間通信性能差的問題。首先將所需的tokens通過跨機(jī)AllGather同步到機(jī)間,然后在機(jī)間進(jìn)行tokens的排序與AlltoAll通信。基于這種分層的通信方式降低了跨機(jī)通信數(shù)據(jù)量,有效地提升了整體通信性能。經(jīng)過在DeepSeek V3 671B實(shí)訓(xùn)測(cè)試,在EP=16時(shí)端到端吞吐性能提升15%。機(jī)間通信合并與原始通信方案的示意如圖1。

圖1. 機(jī)間通信合并與原始通信方案的示意圖
AlltoAllV收發(fā)異構(gòu)復(fù)用特性
在MoE的token dispatch 以及 token combine階段各需要執(zhí)行一次AlltoAllV的通信計(jì)算。在下發(fā)AlltoAllV算子時(shí)需要send_list/receive_list的參數(shù)信息,而這兩個(gè)參數(shù)內(nèi)存在device側(cè),需要對(duì)其進(jìn)行一次device to host操作將其搬運(yùn)至Host側(cè)內(nèi)存。因此在正向token dispatch及token combine階段各存在1次因device to host引發(fā)的下發(fā)斷流(即,下發(fā)流程需要等待device to host操作完成后,才能下發(fā)其余算子)。如果考慮反向計(jì)算,斷流次數(shù)就變成4次,對(duì)性能造成嚴(yán)重影響。
為此,昇思MindSpore采用AlltoAllV收發(fā)異構(gòu)復(fù)用技術(shù)來減少斷流次數(shù),其核心思想在于在提前對(duì)token dispatch的send_list/receive_list進(jìn)行device to host,將其緩存在Host,然后基于緩存的send_list/receive_list實(shí)現(xiàn)提前下發(fā)token combine階段的AlltoAllV,其原理如圖2所示。
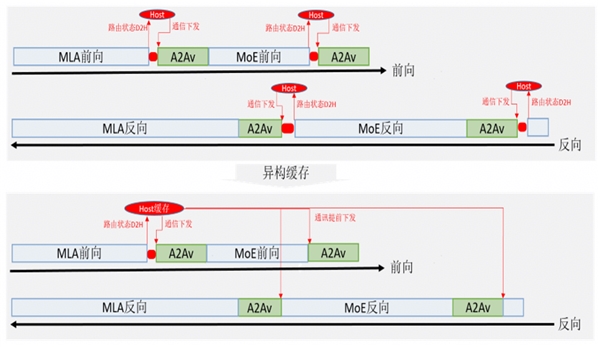
圖2. AlltoAllV收發(fā)異構(gòu)復(fù)用
昇思MindSpore通過其異構(gòu)能力實(shí)現(xiàn)AlltoAllV收發(fā)send_list/receive_list的異構(gòu)復(fù)用,將斷流次數(shù)從4次降低到1次。在DeepSeek V3 671B實(shí)訓(xùn)測(cè)試,端到端性能提升5%。
昇思MindSpore針對(duì)MoE性能提升的業(yè)界難題,成體系地采用優(yōu)化技術(shù),包括但不限于上述2項(xiàng)技術(shù),構(gòu)筑了昇思MindSpore面向超大規(guī)模MoE訓(xùn)練的高效通信底座,更多的技術(shù)介紹與交流,請(qǐng)關(guān)注昇思人工智能框架峰會(huì)。
本次在杭州舉辦的昇思人工智能框架峰會(huì),將會(huì)邀請(qǐng)思想領(lǐng)袖、專家學(xué)者、企業(yè)領(lǐng)軍人物及明星開發(fā)者等產(chǎn)學(xué)研用代表,共探技術(shù)發(fā)展趨勢(shì)、分享創(chuàng)新成果與實(shí)踐經(jīng)驗(yàn)。歡迎各界精英共赴前沿之約,攜手打造開放、協(xié)同、可持續(xù)的人工智能框架新生態(tài)!

關(guān)注我們


